Simulation methods
Krystian Igras
2023-02-08
Source:vignettes/simulation_methods.Rmd
simulation_methods.RmdDataFakeR offers various methods for defining how exactly each column should be simulated.
We can highlight the below four simulation method types:
- Deterministic (formula or constraint-based) simulation.
- Special method simulation.
- Restricted simulation.
- Default simulation.
The package tries to simulate the column with each method, with preserving the order of the above list.
That means, the package will try to simulate the column using special method first and when such method cannot be executed (the conditions for running such method are not met) then, the next method is applied. More to that when one of the methods successfully generated the data, the following ones are skipped.
The goal of this document is to describe each method providing required details and, if applied, provide an information how each method can be customized.
Deterministic (formula or constraint-based) simulation.
Let’s imagine we want to generate tables that reflects standard database used in the library. One of the tables used there, can be the one describing all the books owned by the library.
The YAML configuration of such table can have a form:
# schema-books.yml
public:
tables:
books:
columns:
book_id:
type: char(12)
author:
type: varchar
title:
type: varchar
genre:
type: varchar
bought:
type: date
amount:
type: smallint
purchase_id:
type: varcharWhile running the standard simulation process we get the following result:
set.seed(123)
sch <- schema_source(system.file("extdata", "schema-books.yml", package = "DataFakeR"))
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title genre bought amount purchase_id
#> <chr> <chr> <chr> <chr> <date> <int> <chr>
#> 1 OoVtwCbu QJoEYa XLaS xljCUY 1971-02-17 -28970 ZUYlCSp
#> 2 cXxXjdFu fRZxZuvf h dkvg 1982-12-06 -6823 rMSssP
#> 3 MCRxukhz VHwPDx TSbmLV WcDNUKrH 1999-06-19 -28513 H
#> 4 ikcePHyu lHcxeV NgJ pci 2018-07-04 -17965 kFBzBRvgOm
#> 5 jpBYnLQM hQQLTzI smigTbte IgQl 2012-03-14 -29188 rQZkhhyVGb
#> 6 HVVTHHMY E rQk Uyyl 1983-05-07 11159 L
#> 7 NsCWpGdK Hjguim NeZNdvuO NLeNbo 1996-09-13 -13255 ZTzULgHyaI
#> 8 GnuTiETO bi Q I 2016-05-26 -26167 g
#> 9 qXqqpWng q zgwYViH VYtwtjxadR 1994-08-08 -28056 ziVQrHKuQS
#> 10 kAYLTfSF oy dMyfaUt SBat 2010-05-15 24932 oKAVZEven though many columns don’t look realistic let’s take care of
book_id and purchase_id columns. From the
rules followed in the library, we know that:
-
book_idis the concatenation of first 4 letters fromauthor,titleandbought, -
purchase_idis concatenation of word ‘purchase_’ and columnbought(such rule is checked by SQLpurchase_id = 'purchase_' || boughtcheck constraint).
If we want to preserve such rules, we have two options:
- store the rules as
check_constraintsrewritten in R code, - define
book_idandpurchase_idusing formula.
Let’s describe purchase_id using the first method:
# schema-books_2.yml
public:
tables:
books:
columns:
book_id:
type: char(12)
author:
type: varchar
title:
type: varchar
genre:
type: varchar
bought:
type: date
amount:
type: smallint
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)let’s update the source and plot column dependencies:
sch <- schema_update_source(sch, file = system.file("extdata", "schema-books_2.yml", package = "DataFakeR"))
schema_plot_deps(sch, "books")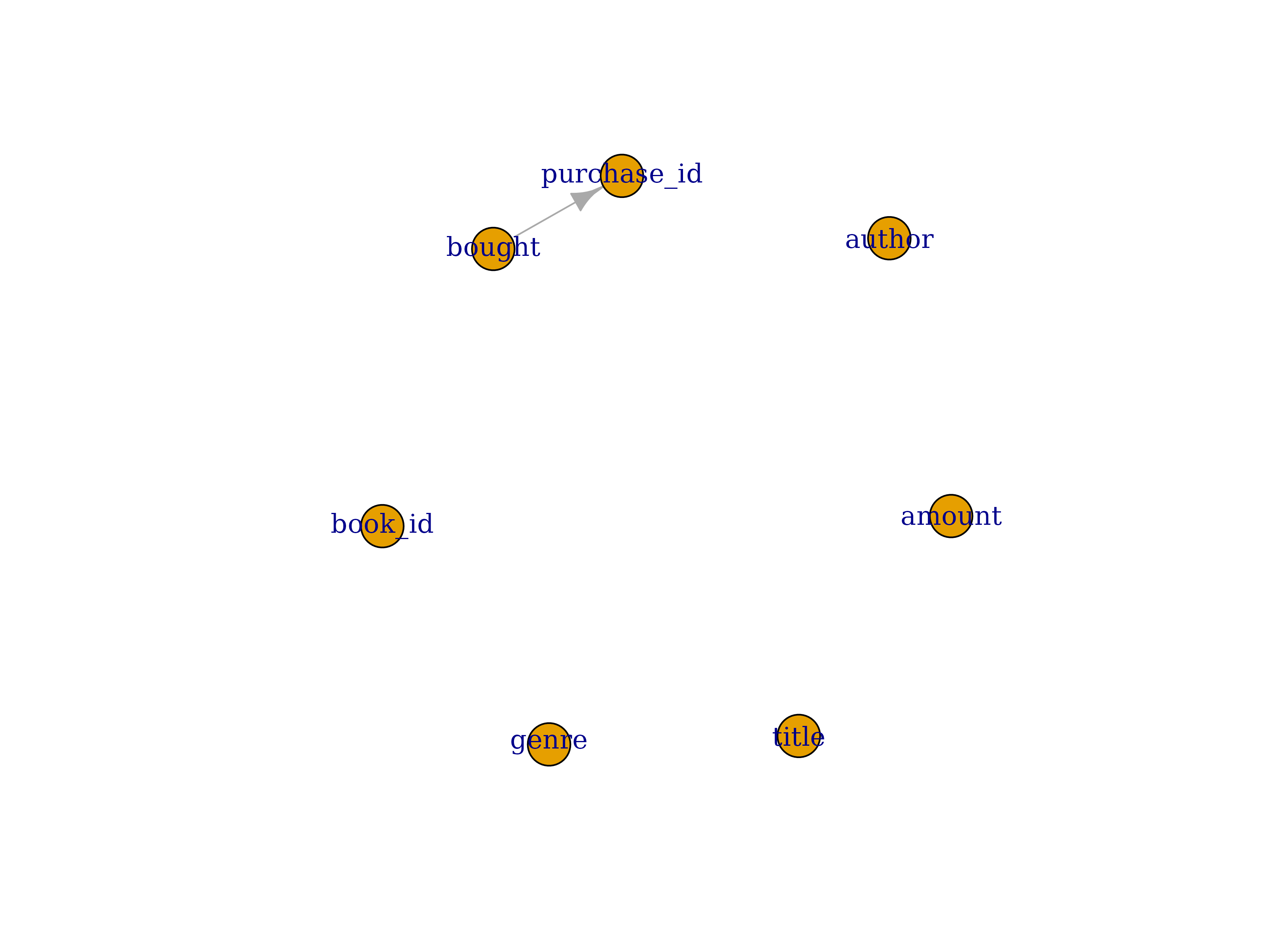
As you can see DataFakeR detected dependency between
purchase_id and bought column. More to that
the package will assure bought column will be simulated
before purchase_id.
Let’s take a quick look at the data:
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title genre bought amount
#> <chr> <chr> <chr> <chr> <date> <int>
#> 1 obYnWkze leZ eH wuPcdqB 1974-04-22 31400
#> 2 suceMctW DIrDylVHb Sh dN 1996-09-09 25250
#> 3 JKZRpDRU jYbVn hTSTv jKJuYWecg 2016-03-15 32340
#> 4 SjiJcVUe NsuEksi nHRMIyFD gHPn 2009-12-05 -8172
#> 5 VCfOjSus noTSZCjxmI mGAsRZdF gh 1988-05-11 -10032
#> 6 RwvBDkNJ CawvEUAyr EtaZmIBeJK wfmIn 1971-06-20 18227
#> 7 EngSilEF AD xINeIh oKVd 1973-07-07 -23221
#> 8 axJdjADg ZV KbRddOMueZ ZfONo 2000-12-14 202
#> 9 pzZxHxYI rEk nCggoULhXd cIy 1976-06-19 15893
#> 10 UqSzDjOO BdRqmjgd mHbGe ZILkFHVh 2015-05-15 -19569
#> purchase_id
#> <chr>
#> 1 purchase_1974-04-22
#> 2 purchase_1996-09-09
#> 3 purchase_2016-03-15
#> 4 purchase_2009-12-05
#> 5 purchase_1988-05-11
#> 6 purchase_1971-06-20
#> 7 purchase_1973-07-07
#> 8 purchase_2000-12-14
#> 9 purchase_1976-06-19
#> 10 purchase_2015-05-15As we can see check constraint rule was applied to correctly create
purchase_id column.
Note: Check constraint expressions are used to
detect column dependency and to create the checked column, only when the
ones are equality expressions (that means the expression contains
== operator). Such expression assures the column definition
is deterministic. In the future releases (depending on the user’s needs)
the check expression rule can be extended to the cases where expression
constains < and > operators.
Now let’s take care to assure that book_id is the first
8 letters of concatenation of author, title
and bought-year. Such example can be also described using
check constraint, but we’ll use a different method that opens various
options for defining column rules.
If you want to create a column using custom expression, you pass it
as a formula parameter in yaml configuration file. In our
case, we want book_id be created with expression
paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4)).
Let’s put it in configuration as formula parameter:
# schema-books_3.yml
public:
tables:
books:
columns:
book_id:
type: char(12)
formula: !expr paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4))
author:
type: varchar
title:
type: varchar
genre:
type: varchar
bought:
type: date
amount:
type: smallint
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)Again, update the source and plot column dependencies:
sch <- schema_update_source(sch, file = system.file("extdata", "schema-books_3.yml", package = "DataFakeR"))
schema_plot_deps(sch, "books")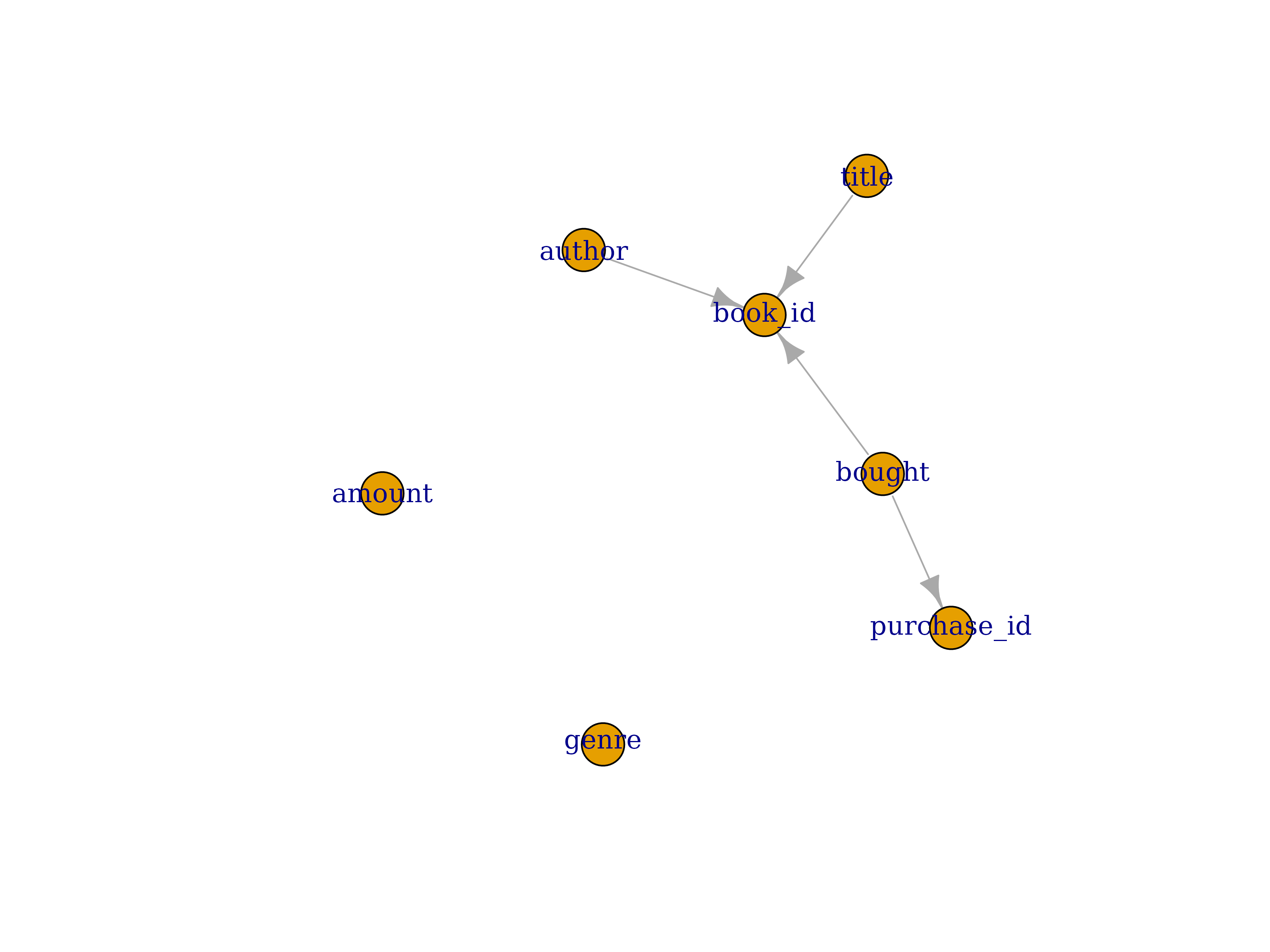
The column dependencies are detected correctly. Let’s move then to simulation step:
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title genre bought amount
#> <chr> <chr> <chr> <chr> <date> <int>
#> 1 vTcK2007 vTc K vwHCWAF 2007-06-14 -17869
#> 2 oYJHqbnQ1997 oYJHEpyDP qbnQ a 1997-03-16 11240
#> 3 PyfNq2007 Pyf Nq wEcoZjiczZ 2007-03-16 -15864
#> 4 QDiNxcpm1979 QDiNktG xcpmbzYN Nm 1979-05-20 -32045
#> 5 vLKIkQH1974 vLK IkQH ipc 1974-04-06 638
#> 6 yvZMNMnt1982 yvZMs NMnt s 1982-07-03 24789
#> 7 wCQqZYEh2014 wCQqGTzWP ZYEhJMaXH dZt 2014-01-05 -4823
#> 8 PdYrIPlM1988 PdYrd IPlM GebYogVMQy 1988-05-13 -30463
#> 9 jCWJ2003 jCW J ayYLMBSykj 2003-03-16 -18411
#> 10 KKjBfTy1977 KKjBXmcVTU fTy qEq 1977-10-21 18874
#> purchase_id
#> <chr>
#> 1 purchase_2007-06-14
#> 2 purchase_1997-03-16
#> 3 purchase_2007-03-16
#> 4 purchase_1979-05-20
#> 5 purchase_1974-04-06
#> 6 purchase_1982-07-03
#> 7 purchase_2014-01-05
#> 8 purchase_1988-05-13
#> 9 purchase_2003-03-16
#> 10 purchase_1977-10-21As we can see the result is again as expected.
Note The formula expression is passed to
dplyr::mutate in the implementation, which means you may
use in the formula any dplyr-specific functions, such as
n().
Note Formula-based column definition was classified
as a ‘Deterministic simulation’ method, but you may also define formulas
with random sampling inside. For example assuring that column
end_date have values larger than start_date
you may define:
formula: start_date + sample(1:10, dplyr::n(), replace = TRUE).
Special method simulation
Let’s take a look at the last simulated data:
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title genre bought amount
#> <chr> <chr> <chr> <chr> <date> <int>
#> 1 vTcK2007 vTc K vwHCWAF 2007-06-14 -17869
#> 2 oYJHqbnQ1997 oYJHEpyDP qbnQ a 1997-03-16 11240
#> 3 PyfNq2007 Pyf Nq wEcoZjiczZ 2007-03-16 -15864
#> 4 QDiNxcpm1979 QDiNktG xcpmbzYN Nm 1979-05-20 -32045
#> 5 vLKIkQH1974 vLK IkQH ipc 1974-04-06 638
#> 6 yvZMNMnt1982 yvZMs NMnt s 1982-07-03 24789
#> 7 wCQqZYEh2014 wCQqGTzWP ZYEhJMaXH dZt 2014-01-05 -4823
#> 8 PdYrIPlM1988 PdYrd IPlM GebYogVMQy 1988-05-13 -30463
#> 9 jCWJ2003 jCW J ayYLMBSykj 2003-03-16 -18411
#> 10 KKjBfTy1977 KKjBXmcVTU fTy qEq 1977-10-21 18874
#> purchase_id
#> <chr>
#> 1 purchase_2007-06-14
#> 2 purchase_1997-03-16
#> 3 purchase_2007-03-16
#> 4 purchase_1979-05-20
#> 5 purchase_1974-04-06
#> 6 purchase_1982-07-03
#> 7 purchase_2014-01-05
#> 8 purchase_1988-05-13
#> 9 purchase_2003-03-16
#> 10 purchase_1977-10-21As we mentioned in the previous section, we’re not happy with the
result of multiple column values. In this section we’ll take of the
result of author and title columns.
In case of author column, we’d like the values to be
random, human readable names. Across R packages, there are many that
offer such functionality. In case of DataFakeR, it’s just enough to
define spec: name for the column definition:
# schema-books_4.yml
public:
tables:
books:
columns:
book_id:
type: char(12)
formula: !expr paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4))
author:
type: varchar
spec: name
title:
type: varchar
genre:
type: varchar
bought:
type: date
amount:
type: smallint
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)Again, update the source and plot column dependencies:
sch <- schema_update_source(sch, file = system.file("extdata", "schema-books_4.yml", package = "DataFakeR"))
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title genre bought amount
#> <chr> <chr> <chr> <chr> <date> <int>
#> 1 Mr. eQDr1993 Mr. Elmore Hane eQDr rXovvKYq 1993-06-21 7005
#> 2 SallOOPF1984 Sally Lubowitz OOPFG HN 1984-10-31 3054
#> 3 AgushEpx1980 Agustus Schmidt hEpx X 1980-09-29 -20733
#> 4 Dr. PdAf1972 Dr. Fabiola Huels PdAfHpFVNp RoTqbvVY 1972-07-07 29393
#> 5 Dr. SUrn1988 Dr. Harper Kunze SUrn Hx 1988-05-10 -24386
#> 6 DonnEDO1973 Donny Wuckert EDO PLVA 1973-04-22 -18597
#> 7 AnicJ2013 Anice Jones PhD J cejZnE 2013-12-28 15596
#> 8 TavaLUwY2021 Tavaris Dicki LUwYDHD NcfFH 2021-06-03 18248
#> 9 Hughbsga2018 Hugh Corkery bsgaYOAM KHvuAXgM 2018-12-30 -7676
#> 10 ParajAXf1973 Paralee King jAXf QmNicoQmP 1973-03-18 -14651
#> purchase_id
#> <chr>
#> 1 purchase_1993-06-21
#> 2 purchase_1984-10-31
#> 3 purchase_1980-09-29
#> 4 purchase_1972-07-07
#> 5 purchase_1988-05-10
#> 6 purchase_1973-04-22
#> 7 purchase_2013-12-28
#> 8 purchase_2021-06-03
#> 9 purchase_2018-12-30
#> 10 purchase_1973-03-18Voila!
How does it work?
Whenever you precise spec parameter to the column,
DataFakeR will look for the simulation options if the special method
with such name was defined. For the specific column type, such option is
defined at options$opt_simul_spec_<column-type>.
So for the default options and character column type, we have:
default_faker_opts$opt_simul_spec_character
#> $name
#> function (n, not_null, unique, default, spec_params, na_ratio,
#> levels_ratio, ...)
#> {
#> call_args <- names(sys.call())
#> if (!"spec_params" %in% call_args) {
#> spec_params <- list()
#> }
#> spec_params$n <- n
#> unique_sample(do.call(charlatan::ch_name, spec_params), spec_params = spec_params,
#> unique = unique) %>% levels_rand(unique = unique, levels_ratio = levels_ratio) %>%
#> na_rand(not_null = not_null, na_ratio = na_ratio)
#> }
#> <bytecode: 0x556429d76c80>
#> <environment: namespace:DataFakeR>The name method was defined and we were able to use it
in the simulation. Looking at the function body, we may see it uses
charlatan::ch_name function to simulate human-readable
names.
What else can we spot regarding the method definition? The below points are worth notice:
- the method have
nparameter. This is obligatory parameter for each simulation method. - the method parameters also contain standard column ones from YAML file. Whenever you need access to column parameters, just define them while creating the method. DataFakeR passes all the column parameters (not only the default ones) to each method.
- if the parameter is not directly defined in the function it’s still possible to access all of them by parsing ellipsis (…). Please make sure ellipsis is always added as a function parameter.
- by defining
spec_paramsyaml configuration parameter you may access and parse them directly in the method definition. Such parameter allows to resolve conflicts with standard parameters names when duplication exist.
Now, let’s take care of preparing human-readable title. For this case we’ll create our custom function. The titles will consist of combination of four words from predefined values:
books <- function(n) {
first <- c("Learning", "Amusing", "Hiding", "Symbols", "Hunting", "Smile")
second <- c("Of", "On", "With", "From", "In", "Before")
third <- c("My", "Your", "The", "Common", "Mysterious", "A")
fourth <- c("Future", "South", "Technology", "Forest", "Storm", "Dreams")
paste(sample(first, n), sample(second, n), sample(third, n), sample(fourth, n))
}Let’s check a few possible results:
books(3)
#> [1] "Hiding On Common South" "Smile With My Forest"
#> [3] "Amusing Of Mysterious Dreams"Perfect!
In order to present how spec_params can be used let’s
add an option to skip the second word in the result:
books <- function(n, add_second = FALSE) {
first <- c("Learning", "Amusing", "Hiding", "Symbols", "Hunting", "Smile")
second <- c("Of", "On", "With", "From", "In", "Before")
third <- c("My", "Your", "The", "Common", "Mysterious", "A")
fourth <- c("Future", "South", "Technology", "Forest", "Storm", "Dreams")
second_res <- NULL
if (add_second) {
second_res <- sample(second, n, replace = TRUE)
}
paste(
sample(first, n, replace = TRUE), second_res,
sample(third, n, replace = TRUE), sample(fourth, n, replace = TRUE)
)
}Now, let’s create the final method to use in the workflow.
The function needs to:
- take
nparameter, - optional standard parameter
unique(we’ll use it to assure unique results are returned), -
spec_paramsthat allows us to modify special method parameters
simul_spec_character_book <- function(n, unique, spec_params, ...) {
spec_params$n <- n
DataFakeR::unique_sample(
do.call(books, spec_params),
spec_params = spec_params, unique = unique
)
}Before we run the example, let’s explain code blocks in function definition.
We’re evaluating books using do.call.
That’s why we need to store all the parameters in the list passed to
do.call. The only missing one is n, so:
spec_params$n <- nWe allowed our method to respect unique parameter,
that’s why we want to assure the returned sample is unique. We may
achieve this using DataFakeR::unique_sample.
The function evaluates sampling expression multiple times, replacing duplicated values with the new ones. It’s worth to mention some of the function parameters:
-
sim_expr- simulation expression to be evaluated, -
...- parameters values used insim_expr, -
unique- if TRUE, the function will try to generate unique values, -
n_iter- number of iteration to try generate unique value.
So it’s enough to define:
DataFakeR::unique_sample(
sim_expr = do.call(books, spec_params),
spec_params = spec_params, unique = unique
)Let’s modify configuration file with the book method
(with using spec_params to simulate full title):
schema-books_5.yml
public:
tables:
books:
columns:
book_id:
type: char(8)
formula: !expr paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4))
author:
type: varchar
spec: name
title:
type: varchar
spec: book
spec_params:
add_second: true
genre:
type: varchar
bought:
type: date
amount:
type: smallint
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)and define the new method in the package options:
my_opts <- set_faker_opts(
opt_simul_spec_character = opt_simul_spec_character(book = simul_spec_character_book)
)
sch <- schema_source(
system.file("extdata", "schema-books_5.yml", package = "DataFakeR"),
faker_opts = my_opts
)
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title
#> <chr> <chr> <chr>
#> 1 AliaSymb2005 Alia Thiel Symbols With My Storm
#> 2 FlorHidi1973 Florida Gottlieb Hiding From Common Technology
#> 3 RitaSmil1978 Rita Volkman PhD Smile On The Future
#> 4 Mrs.Amus1974 Mrs. Prudence Deckow DDS Amusing From Common Future
#> 5 AlviSymb2004 Alvis Wolf Symbols Before Common Forest
#> 6 LindSmil1985 Lindell Abshire Smile In Your Dreams
#> 7 KareHidi1976 Kareem Kshlerin IV Hiding On A Storm
#> 8 CarrSmil1985 Carrie McDermott Smile Before Common South
#> 9 DevoLear2013 Devonte Hansen Learning Before The Storm
#> 10 AleaHunt1987 Alease Pouros Hunting From The Future
#> genre bought amount purchase_id
#> <chr> <date> <int> <chr>
#> 1 mKVIeGGTy 2005-05-12 15135 purchase_2005-05-12
#> 2 dUnXYSEI 1973-04-24 -5641 purchase_1973-04-24
#> 3 npNBcTycf 1978-02-13 27090 purchase_1978-02-13
#> 4 DostQ 1974-05-05 -24378 purchase_1974-05-05
#> 5 CmGBYUpbPE 2004-03-03 29926 purchase_2004-03-03
#> 6 mqIf 1985-08-30 5654 purchase_1985-08-30
#> 7 kYodnY 1976-08-03 -31808 purchase_1976-08-03
#> 8 tmPdYwb 1985-07-31 19944 purchase_1985-07-31
#> 9 RSqpcXzQa 2013-12-18 19069 purchase_2013-12-18
#> 10 Wc 1987-04-18 27308 purchase_1987-04-18Great! We’ve managed to use our custom special method to simulate human-readable titles.
For the last part of this section it’s worth to mention the remaining
special methods for each column type. For numeric, integer, logical and
Date column classes, DataFakeR offer spec: distr method
that allow to simulate column from the selected distribution. The method
requires to provide:
spec_params:
method: <method-name>where method name is the name of simulation function such as
rnorm, rbinom etc.
For example, in order to simulate the column from normal distribution
with mean = 10 and sd = 5 we should
define:
spec: distr
spec_params:
method: rnorm
mean: 10
sd: 5Restricted simulation
Restricted simulation methods allow to simulate data considering exceptional parameters defined for each column.
Such parameters can be for example:
-
values- possible column values for the target column -
range- possible column values range for the target column
All the restricted methods offered by DataFakeR for column type are
defined in
default_faker_opts$opt_simul_restricted_<column-type>.
Let’s take a look what methods are offered for integer columns:
default_faker_opts$opt_simul_restricted_integer
#> $f_key
#> function (n, not_null, unique, default, type, values, na_ratio,
#> levels_ratio, ...)
#> {
#> if (isTRUE(not_null)) {
#> values <- values[!is.na(values)]
#> }
#> if (isTRUE(unique)) {
#> warning("Requested to simulate foreign key having unique values. Make sure config is correctly defined.")
#> }
#> sample(values, n, replace = !unique) %>% na_rand(not_null = not_null,
#> na_ratio = na_ratio)
#> }
#> <bytecode: 0x556429d9e520>
#> <environment: namespace:DataFakeR>
#>
#> $in_set
#> function (n, not_null, unique, default, type, values, na_ratio,
#> levels_ratio, ...)
#> {
#> if (!missing(values)) {
#> if (isTRUE(not_null)) {
#> values <- values[!is.na(values)]
#> }
#> return(sample(values, n, replace = !unique) %>% na_rand(not_null = not_null,
#> na_ratio = na_ratio))
#> }
#> return(NULL)
#> }
#> <bytecode: 0x556429da12e8>
#> <environment: namespace:DataFakeR>
#>
#> $range
#> function (n, not_null, unique, default, type, range, na_ratio,
#> levels_ratio, ...)
#> {
#> if (!missing(range)) {
#> return(unique_sample(round(stats::runif(n, range[1],
#> range[2])), range = range, n = n, unique = unique) %>%
#> na_rand(not_null = not_null, na_ratio = na_ratio))
#> }
#> return(NULL)
#> }
#> <bytecode: 0x556429da0210>
#> <environment: namespace:DataFakeR>We can see there are three methods defined:
-
f_key- restricted method responsible for simulating foreign keys (we’ll come back to this one in the last part of the section), -
range- method takingrangeparameter. Whenrangeis missingNULLis returned, otherwise integers betweenrange[1]andrange[2]are returned, -
in_set- method takingvaluesparameter. Whenvaluesis missingNULLis returned, otherwise sampled values fromvaluesare returned.
Let’s highlight the general rule for restricted methods used by the
package (excluding f_key one):
- each method has
nas obligatory parameter that determines number of returned values, - standard column parameters (
not_null,unique,type) are optional but respected, - the method usually have defined ‘restriction’ parameter that determines whether the method should be applied or not,
- when restriction condition is not met (for example ‘restriction’
parameter is missing) the method should return
NULL.
The last point allows DataFakeR to scan across all the restriction
methods. When a method returns NULL result, the package
moves to simulate from the next method defined in
opt_simul_restricted_<column-type> setting.
Similar to special methods, you may also define a set of your custom restricted methods. You may achieve this by setting up new methods with:
set_faker_opts(
opt_simul_restricted_<column-type> = opt_simul_restricted_<column-type>(my_method = method, ...)
)Note: DataFakeR allow also to rewrite currently
existing method. So whenever you need to rewrite for example
in_set method, just specify it as above.
Having the knowledge about restricted methods, let’s use them to
generate amount column from values between 1
and 99. We’ll do it by using range method for
amount column:
# schema-books_6.yml
public:
tables:
books:
columns:
book_id:
type: char(8)
formula: !expr paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4))
author:
type: varchar
spec: name
title:
type: varchar
spec: book
spec_params:
add_second: true
genre:
type: varchar
bought:
type: date
amount:
type: smallint
range: [1, 99]
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)
sch <- schema_update_source(sch, system.file("extdata", "schema-books_6.yml", package = "DataFakeR"))
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title
#> <chr> <chr> <chr>
#> 1 BranLear1997 Branson Kerluke Learning From A South
#> 2 AutrSmil1998 Autry Brakus Smile From A Storm
#> 3 Ms. Lear1970 Ms. Delphia Yundt DVM Learning From Your Storm
#> 4 TeniHidi2003 Tenisha Beier Hiding From Mysterious South
#> 5 MilfSmil1997 Milford Stanton-VonRueden Smile With Mysterious South
#> 6 IvorHidi1996 Ivory Fahey Hiding Of My Forest
#> 7 MelbLear1984 Melba Lehner Learning With Common Technology
#> 8 Mrs.Amus2017 Mrs. Malaya Wolf DVM Amusing On My Storm
#> 9 Dr. Symb2013 Dr. Tabetha Ferry Symbols Of Your Forest
#> 10 MeyeSymb2002 Meyer Stamm-Hintz Symbols From Mysterious Storm
#> genre bought amount purchase_id
#> <chr> <date> <int> <chr>
#> 1 ysosUqWUZ 1997-10-07 75 purchase_1997-10-07
#> 2 CFDcnO 1998-01-05 52 purchase_1998-01-05
#> 3 ATojacy 1970-11-01 97 purchase_1970-11-01
#> 4 QZnAjphst 2003-03-03 11 purchase_2003-03-03
#> 5 RQTDi 1997-07-04 59 purchase_1997-07-04
#> 6 lfwZjb 1996-08-26 86 purchase_1996-08-26
#> 7 TyqsEy 1984-02-23 32 purchase_1984-02-23
#> 8 oRjRQTg 2017-09-10 64 purchase_2017-09-10
#> 9 nTyuinThgz 2013-09-09 66 purchase_2013-09-09
#> 10 ToWVIacj 2002-08-16 92 purchase_2002-08-16Awesome! Let’s simulate now human-readable book genre from a set of
defined values. We can achieve this using in_set method for
character column type:
default_faker_opts$opt_simul_restricted_character$in_set
#> function (n, not_null, unique, default, nchar, type, values,
#> na_ratio, levels_ratio, ...)
#> {
#> if (!missing(values)) {
#> if (isTRUE(not_null)) {
#> values <- values[!is.na(values)]
#> }
#> return(sample(values, n, replace = !unique) %>% na_rand(not_null = not_null,
#> na_ratio = na_ratio))
#> }
#> return(NULL)
#> }
#> <bytecode: 0x556429d80548>
#> <environment: namespace:DataFakeR>So let’s assume we want the genre to be simulated from set:
Fantasy, Adventure, Horror,
Romance.
Let’s define such set as possible values for
genre column:
schema-books_7.yml
public:
tables:
books:
columns:
book_id:
type: char(8)
formula: !expr paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4))
author:
type: varchar
spec: name
title:
type: varchar
spec: book
spec_params:
add_second: true
genre:
type: varchar
values: [Fantasy, Adventure, Horror, Romance]
bought:
type: date
amount:
type: smallint
range: [1, 99]
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)
sch <- schema_update_source(sch, system.file("extdata", "schema-books_7.yml", package = "DataFakeR"))
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title
#> <chr> <chr> <chr>
#> 1 RylaHidi1970 Rylan Prosacco Hiding From The Dreams
#> 2 TripAmus1979 Tripp Armstrong Amusing From Mysterious Future
#> 3 TainSmil1999 Taina Steuber Smile In Mysterious Storm
#> 4 Ova Lear2020 Ova Hettinger Learning With The Technology
#> 5 Dr. Lear1994 Dr. Alphonse Watsica Sr. Learning In A Technology
#> 6 DevoSmil1975 Devonte McClure Smile Before The Forest
#> 7 ConaLear2019 Conard Volkman-Walker Learning In A Future
#> 8 EloySymb1982 Eloy Ratke III Symbols Before A Forest
#> 9 PhoeSymb1975 Phoebe Swaniawski Symbols On Mysterious Dreams
#> 10 AdelSymb1997 Adeline Block PhD Symbols With Common Dreams
#> genre bought amount purchase_id
#> <chr> <date> <int> <chr>
#> 1 Adventure 1970-09-14 98 purchase_1970-09-14
#> 2 Romance 1979-11-11 46 purchase_1979-11-11
#> 3 Horror 1999-12-14 44 purchase_1999-12-14
#> 4 Romance 2020-02-18 19 purchase_2020-02-18
#> 5 Adventure 1994-06-04 39 purchase_1994-06-04
#> 6 Fantasy 1975-06-09 95 purchase_1975-06-09
#> 7 Romance 2019-06-17 17 purchase_2019-06-17
#> 8 Adventure 1982-02-11 38 purchase_1982-02-11
#> 9 Romance 1975-05-07 7 purchase_1975-05-07
#> 10 Romance 1997-02-05 28 purchase_1997-02-05Let’s add the last improvement by specifying date range for books:
schema-books_8.yml
public:
tables:
books:
columns:
book_id:
type: char(8)
formula: !expr paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4))
author:
type: varchar
spec: name
title:
type: varchar
spec: book
spec_params:
add_second: true
genre:
type: varchar
values: [Fantasy, Adventure, Horror, Romance]
bought:
type: date
range: ['2020-01-02', '2021-06-01']
amount:
type: smallint
range: [1, 99]
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)
sch <- schema_update_source(sch, system.file("extdata", "schema-books_8.yml", package = "DataFakeR"))
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title
#> <chr> <chr> <chr>
#> 1 DomoHunt2021 Domonique Hettinger Hunting In Mysterious Storm
#> 2 ShaeHidi2020 Shae Daugherty Hiding Before Mysterious Future
#> 3 HopeHunt2020 Hope Murphy-Cremin Hunting On Common Forest
#> 4 MalaSmil2020 Malaya Rippin-Feil Smile Of Your Technology
#> 5 ChriSmil2021 Christoper Kerluke Smile Of My Dreams
#> 6 LeeaLear2020 Leeann Rice Learning In Your Storm
#> 7 Mrs.Hidi2020 Mrs. Alys Dickinson DVM Hiding On A Storm
#> 8 ChriAmus2020 Christin Padberg DVM Amusing In Common South
#> 9 DeboSmil2020 Debora Schamberger Smile Of The South
#> 10 EzzaHidi2020 Ezzard Keeling Hiding On Your Forest
#> genre bought amount purchase_id
#> <chr> <date> <int> <chr>
#> 1 Adventure 2021-01-02 86 purchase_2021-01-02
#> 2 Fantasy 2020-04-12 10 purchase_2020-04-12
#> 3 Adventure 2020-07-11 15 purchase_2020-07-11
#> 4 Adventure 2020-06-11 78 purchase_2020-06-11
#> 5 Adventure 2021-04-16 48 purchase_2021-04-16
#> 6 Horror 2020-06-05 65 purchase_2020-06-05
#> 7 Romance 2020-08-17 3 purchase_2020-08-17
#> 8 Fantasy 2020-08-02 69 purchase_2020-08-02
#> 9 Horror 2020-05-20 68 purchase_2020-05-20
#> 10 Adventure 2020-09-15 19 purchase_2020-09-15Here we are.
For the last part of restricted methods, let’s add a few words about
f_key restricted method.
As mentioned the method is responsible for simulating foreign key
columns. When the column is defined in schema as a foreign key,
DataFakeR will source possible values from the parent table and pass
such values set as a values parameter to f_key
method.
Simulating foreign key will skip execution of the remaining restricted methods defined in options.
To see it in action, let’s extend our schema definition by adding a
new borrowed table (let’s also precise nrows
for each table).
# schema-books_9.yml
public:
tables:
books:
nrows: 10
columns:
book_id:
type: char(8)
formula: !expr paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4))
author:
type: varchar
spec: name
title:
type: varchar
spec: book
spec_params:
add_second: true
genre:
type: varchar
values: [Fantasy, Adventure, Horror, Romance]
bought:
type: date
range: ['2020-01-02', '2021-06-01']
amount:
type: smallint
range: [1, 99]
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)
borrowed:
nrows: 30
columns:
book_id:
type: char(8)
user_id:
type: char(10)
foreign_keys:
book_id_fkey:
columns: book_id
references:
columns: book_id
table: booksLet’s update the file and check table dependencies:
sch <- schema_update_source(sch, system.file("extdata", "schema-books_9.yml", package = "DataFakeR"))
schema_plot_deps(sch)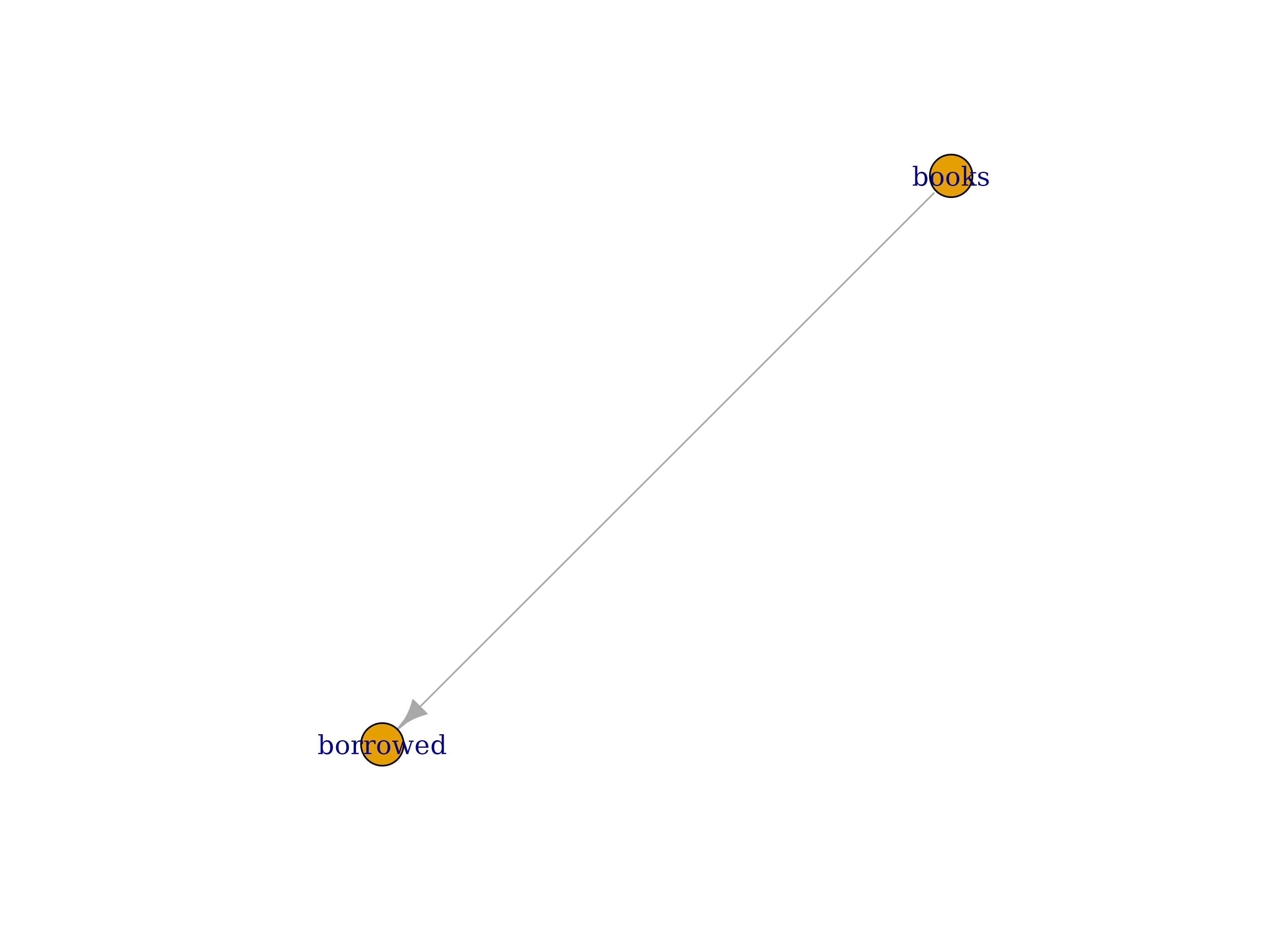
As shown, DataFakeR detected dependency between books
and borrowed, and will generate books table
first to get possible values for foreign key column.
Let’s simulate the data and compare simumlated book ids:
sch <- schema_simulate(sch)
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title genre
#> <chr> <chr> <chr> <chr>
#> 1 ThedSymb2020 Theda Hamill Symbols In The Future Horror
#> 2 QueeLear2021 Queenie Klein-Predovic Learning Of Mysterious Forest Romance
#> 3 AdamAmus2020 Adam Hills Amusing From Common Storm Fantasy
#> 4 BranHunt2021 Brandin Zboncak DDS Hunting On Common Technology Adventure
#> 5 Mrs.Hidi2020 Mrs. Louise Vandervort Hiding From My South Horror
#> 6 Dr. Symb2021 Dr. Clarence Beier Symbols With The Storm Romance
#> 7 ShanHunt2020 Shannon Bode Hunting Of Your Dreams Romance
#> 8 DarrHunt2020 Darrien Schuster Hunting From A Forest Fantasy
#> 9 MariHunt2020 Maritza Mosciski Hunting In The Forest Adventure
#> 10 Mr. Amus2020 Mr. Clinton Herzog DVM Amusing Of Mysterious Future Romance
#> bought amount purchase_id
#> <date> <int> <chr>
#> 1 2020-09-02 62 purchase_2020-09-02
#> 2 2021-01-10 83 purchase_2021-01-10
#> 3 2020-07-22 17 purchase_2020-07-22
#> 4 2021-02-16 49 purchase_2021-02-16
#> 5 2020-01-23 9 purchase_2020-01-23
#> 6 2021-01-20 36 purchase_2021-01-20
#> 7 2020-08-16 52 purchase_2020-08-16
#> 8 2020-06-18 14 purchase_2020-06-18
#> 9 2020-01-19 54 purchase_2020-01-19
#> 10 2020-08-23 89 purchase_2020-08-23
unique(schema_get_table(sch, "borrowed")$book_id)
#> [1] "QueeLear2021" "Mr. Amus2020" NA "AdamAmus2020" "MariHunt2020"
#> [6] "ThedSymb2020" "Mrs.Hidi2020" "BranHunt2021" "DarrHunt2020"So the values were correctly inherited from parent table.
Default simulation
When none of the above methods were applied DataFakeR will simulate
the column using the default method. For each column type you may find
the default methods defined at
default_faker_opts$default_faker_opts$opt_simul_default_fun_<column-type>.
In order to overwrite such method it’s just enough to:
set_faker_opts(
opt_simul_default_fun_<column-type> = my_custom_method
)