Cost distribution among software process activities
3 An R Package Engineering Workflow
R/Pharma workshop: Good Software Engineering Practice for R Packages
Joe Zhu
October 28, 2024
Motivation
From an idea to a production-grade R package
Example scenario: in your daily work, you notice that you need certain one-off scripts again and again.
The idea of creating an R package was born because you understood that “copy and paste” R scripts is inefficient, and on top of that, you want to share your helpful R functions with colleagues and the world…
Professional Workflow

Photo CC0 by ELEVATE on pexels.com
Typical work steps
- Idea
- Concept creation
- Validation planning
- Specification:
- User Requirements Spec (URS),
- Functional Spec (FS), and
- Software Design Spec (SDS)
- Test Plan (TP)
- R package programming
- Documented verification
- Completion of formal validation
- R package release
- Use in production
- Maintenance
Extensive documentation, huge paperwork, lots of manual work, lots of signatures, …
Workflow in Practice

Photo CC0 by Chevanon Photography on pexels.com
Frequently Used Workflow in Practice
- Idea
- R package programming
- Use in production
- Bug fixing
- Use in production
- Bug fixing + Documentation
- Use in production
- Bug fixing + Further development
- Use in production
- Bug fixing + …
Bad practice!
Why?
Why practice good engineering?
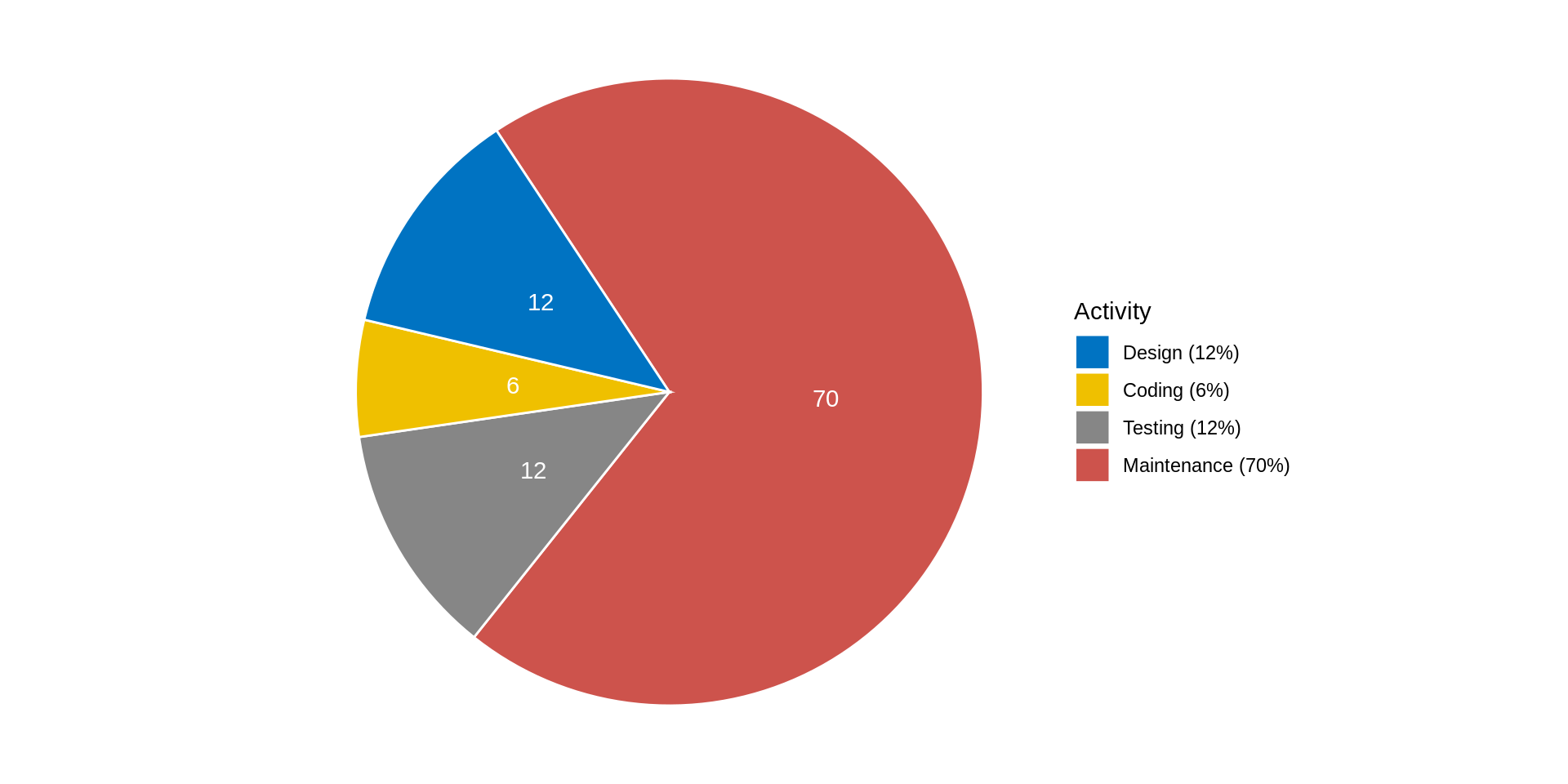
Why practice good engineering?
Origin of errors in system development
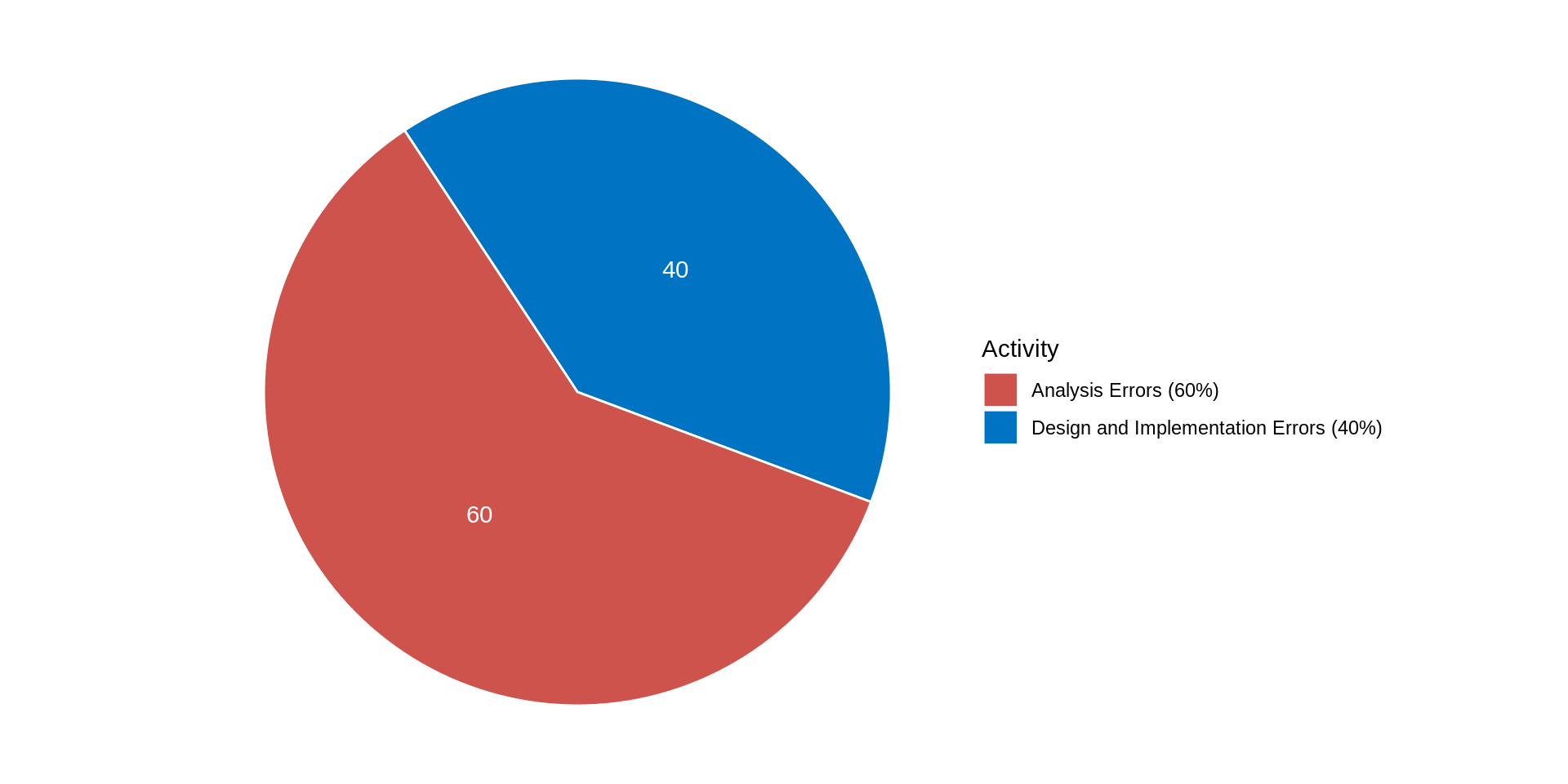
Boehm, B. (1981). Software Engineering Economics. Prentice Hall.
Why practice good engineering?
- Don’t waste time on maintenance
- Be faster with release on CRAN
- Don’t waste time with inefficient and buggy further development
- Fulfill regulatory requirements1
- Save refactoring time when the Proof-of-Concept (PoC) becomes the release version
- You don’t have to be shy any longer about inviting other developers to contribute to the package on GitHub
Why practice good engineering?
Invest time in
- requirements analysis,
- software design, and
- architecture…
… but in many cases the workflow must be workable for a single developer or a small team.
Workable Workflow

Photo CC0 by Kateryna Babaieva on pexels.com
Suggestion for a Workable Workflow
- Idea
- Design docs
- R package programming
- Quality check (see Ensuring Quality)
- Publication
- Use in production
Example - Step 1: Idea
Let’s assume that you used some lines of code to create simulated data in multiple projects:
Idea: put the code into a package
Example - Step 2: Design docs
- Describe the purpose and scope of the package
- Analyse and describe the requirements in clear and simple terms (“prose”)
| Obligation level | Key word1 | Description |
|---|---|---|
| Duty | must2 | “must have” |
| Desire | should | “nice to have” |
| Intention | may | “optional” |
Example - Step 2: Design docs
Purpose and Scope
The R package simulatr is intended to enable the creation of reproducible fake data.
Package Requirements
simulatr must provide a function to generate normal distributed random data for two independent groups. The function must allow flexible definition of sample size per group, mean per group, standard deviation per group. The reproducibility of the simulated data must be ensured via an optional seed. It should be possible to print the function result. The package may also facilitate graphical presentation of the simulated data.
Example - Step 2: Design docs
Useful formats / tools for design docs:
- R Markdown1 (*.Rmd)
- Quarto1 (*.qmd)
- Overleaf2
- draw.io3
UML Diagram
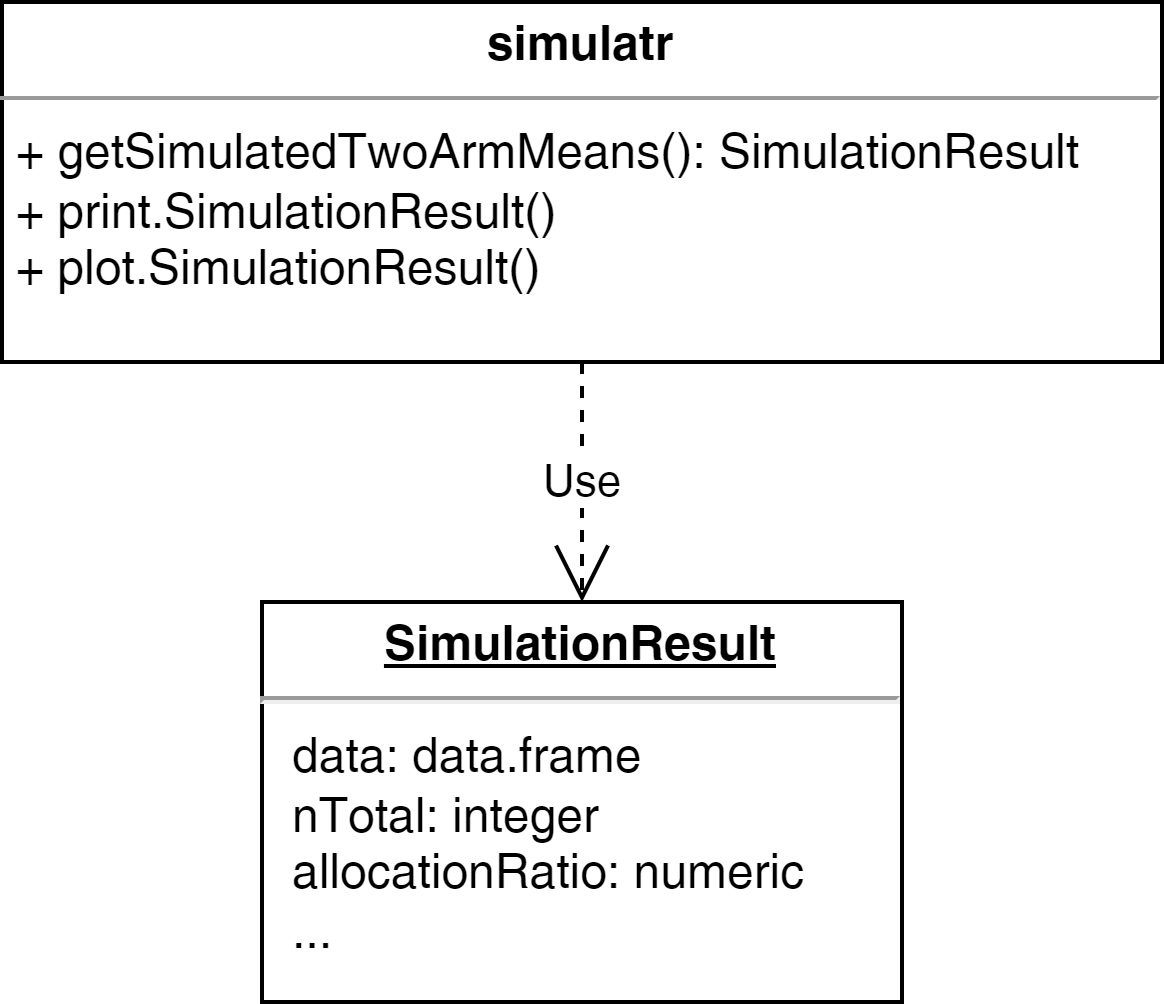
Example - Step 3: Packaging
R package programming
- Create basic package project (see R Packages)
- C&P existing R scripts (one-off scripts, prototype functions) and refactor1 it if necessary
- Create R generic functions
- Document all functions
Example - Step 3: Packaging
One-off script as starting point:
Example - Step 3: Packaging
Refactored script:
Almost all functions, arguments, and objects should be self-explanatory due to their names.
Example - Step 3: Packaging
Define that the result is a list1 which is defined as class2:
getSimulatedTwoArmMeans <- function(n1, n2, mean1, mean2, sd1, sd2) {
result <- list(n1 = n1, n2 = n2,
mean1 = mean1, mean2 = mean2, sd1 = sd1, sd2 = sd2)
result$data <- data.frame(
group = c(rep(1, n1), rep(2, n2)),
values = c(
rnorm(n = n1, mean = mean1, sd = sd1),
rnorm(n = n2, mean = mean2, sd = sd2)
)
)
# set the class attribute
result <- structure(result, class = "SimulationResult")
return(result)
}Example - Step 3: Packaging
The output is impractical, e.g., we need to scroll down:
$n1
[1] 50
$n2
[1] 50
$mean1
[1] 5
$mean2
[1] 7
$sd1
[1] 3
$sd2
[1] 4
$data
group values
1 1 5.53626527
2 1 4.31974157
3 1 7.09586225
4 1 9.81905385
5 1 7.66855581
6 1 7.49156039
7 1 -2.39818485
8 1 10.86783802
9 1 4.81838564
10 1 7.19560045
11 1 2.76588413
12 1 7.72979858
13 1 5.65787736
14 1 7.92959780
15 1 5.32181430
16 1 5.13558650
17 1 2.26968024
18 1 6.14328439
19 1 11.60402155
20 1 4.66401920
21 1 6.30586461
22 1 7.95899890
23 1 2.51373568
24 1 1.72929040
25 1 2.69271376
26 1 8.96892251
27 1 4.73221663
28 1 5.49864839
29 1 1.14832959
30 1 4.11952363
31 1 2.23859437
32 1 1.60026712
33 1 7.45321597
34 1 5.72165838
35 1 9.79113944
36 1 3.64157323
37 1 4.28037944
38 1 3.45142944
39 1 4.51025176
40 1 7.20187919
41 1 2.31165836
42 1 4.32280192
43 1 7.11574959
44 1 4.25983451
45 1 5.00246742
46 1 6.31812829
47 1 3.62197322
48 1 9.74577614
49 1 2.51011438
50 1 6.86766535
51 2 3.39830637
52 2 9.95716487
53 2 5.29955581
54 2 7.39013984
55 2 8.44197588
56 2 11.56031701
57 2 6.47155550
58 2 10.88980472
59 2 5.90957429
60 2 4.28746944
61 2 9.56370691
62 2 12.81882469
63 2 6.78521295
64 2 6.86218160
65 2 3.10197874
66 2 9.77373993
67 2 12.91446536
68 2 0.50270315
69 2 11.35204396
70 2 3.56514026
71 2 -0.06677584
72 2 11.41099888
73 2 6.42409576
74 2 3.99605705
75 2 13.16585029
76 2 2.54253514
77 2 10.22558654
78 2 -5.14300038
79 2 12.99171167
80 2 7.78131137
81 2 7.12656682
82 2 13.81333744
83 2 -0.08281967
84 2 11.09541868
85 2 -1.09221262
86 2 6.62239417
87 2 10.11151094
88 2 -1.08415102
89 2 5.95640699
90 2 0.62913956
91 2 1.00058307
92 2 9.32748681
93 2 1.47461698
94 2 3.22483203
95 2 9.69898562
96 2 16.02206901
97 2 17.01795042
98 2 4.77769511
99 2 5.54388893
100 2 8.35934888
attr(,"class")
[1] "SimulationResult"Solution: implement generic function print
Example - Step 3: Packaging
Generic function print:
#' @title
#' Print Simulation Result
#'
#' @description
#' Generic function to print a `SimulationResult` object.
#'
#' @param x a \code{SimulationResult} object to print.
#' @param ... further arguments passed to or from other methods.
#'
#' @examples
#' x <- getSimulatedTwoArmMeans(n1 = 50, n2 = 50, mean1 = 5,
#' mean2 = 7, sd1 = 3, sd2 = 4, seed = 123)
#' print(x)
#'
#' @export$args
n1 n2 mean1 mean2 sd1 sd2
"50" "50" "5" "7" "3" "4"
$data
# A tibble: 100 × 2
group values
<dbl> <dbl>
1 1 5.54
2 1 4.32
3 1 7.10
4 1 9.82
5 1 7.67
6 1 7.49
7 1 -2.40
8 1 10.9
9 1 4.82
10 1 7.20
# ℹ 90 more rowsExercise

Photo CC0 by Pixabay on pexels.com
Preparation
- Download the unfinished R package simulatr
- Extract the package zip file
- Open the project with RStudio
- Complete the tasks below
Tasks
Add assertions to improve the usability and user experience
Tip on assertions
Use the package checkmate to validate input arguments.
Example:
Error in playWithAssertions(-1) : Assertion on ‘n1’ failed: Element 1 is not >= 1.
Add three additional results:
- n total,
- creation time, and
- allocation ratio
Tip on creation time
Sys.time(), format(Sys.time(), '%B %d, %Y'), Sys.Date()
Add an additional result: t.test result
Add an optional alternative argument and pass it through t.test:
Implement the generic functions print and plot.
Tip on print
Use the plot example function from above and extend it.
Optional extra tasks:
Implement the generic functions
summaryandcatImplement the function
kableknown from the package knitr as generic. Tip: useto define kable as generic
Optional extra task1:
Document your functions with Roxygen2
- If you are already familiar with Roxygen2
References
- Gillespie, C., & Lovelace, R. (2017). Efficient R Programming: A Practical Guide to Smarter Programming. O’Reilly UK Ltd. [Book | Online]
- Grolemund, G. (2014). Hands-On Programming with R: Write Your Own Functions and Simulations (1. Aufl.).
O’Reilly and Associates. [Book | Online] - Rupp, C., & SOPHISTen, die. (2009). Requirements-Engineering und -Management: Professionelle, iterative Anforderungsanalyse für die Praxis (5. Ed.). Carl Hanser Verlag GmbH & Co. KG. [Book]
- Wickham, H. (2015). R Packages: Organize, Test, Document, and Share Your Code (1. Aufl.). O’Reilly and Associates. [Book | Online]
- Wickham, H. (2019). Advanced R, Second Edition.
Taylor & Francis Ltd. [Book | Online]
License information
In the current version, changes were done by (later authors): Andrew Bean Joe Zhu
This work is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
The source files are hosted at github.com/openpharma/workshop-r-swe-rinpharma-2024, which is forked from the original version at github.com/RCONIS/user2024-tutorial-gswep.
Important: To use this work you must provide the name of the creators (initial authors), a link to the material, a link to the license, and indicate if changes were made