
![]()
Overview
DataFakeR is an R package designed to help you generate sample of fake data preserving specified assumptions about the original one.
Installation
- from CRAN
install.packages("DataFakeR")- latest version from Github
remotes::install_github(
"openpharma/DataFakeR"
)Learning DataFakeR
If you are new to DataFakeR, look at the Welcome Page.
You may find there a list of useful articles that will guide you through the package functionality.
Usage
Configure schema YAML structure
# schema_books.yml
public:
tables:
books:
nrows: 10
columns:
book_id:
type: char(8)
formula: !expr paste0(substr(author, 1, 4), substr(title, 1, 4), substr(bought, 1, 4))
author:
type: varchar
spec: name
title:
type: varchar
spec: book
spec_params:
add_second: true
genre:
type: varchar
values: [Fantasy, Adventure, Horror, Romance]
bought:
type: date
range: ['2020-01-02', '2021-06-01']
amount:
type: smallint
range: [1, 99]
na_ratio: 0.2
purchase_id:
type: varchar
check_constraints:
purchase_id_check:
column: purchase_id
expression: !expr purchase_id == paste0('purchase_', bought)
borrowed:
nrows: 30
columns:
book_id:
type: char(8)
not_null: true
user_id:
type: char(10)
foreign_keys:
book_id_fkey:
columns: book_id
references:
columns: book_id
table: booksDefine custom simulation methods if needed
books <- function(n, add_second = FALSE) {
first <- c("Learning", "Amusing", "Hiding", "Symbols", "Hunting", "Smile")
second <- c("Of", "On", "With", "From", "In", "Before")
third <- c("My", "Your", "The", "Common", "Mysterious", "A")
fourth <- c("Future", "South", "Technology", "Forest", "Storm", "Dreams")
second_res <- NULL
if (add_second) {
second_res <- sample(second, n, replace = TRUE)
}
paste(
sample(first, n, replace = TRUE), second_res,
sample(third, n, replace = TRUE), sample(fourth, n, replace = TRUE)
)
}
simul_spec_character_book <- function(n, unique, spec_params, ...) {
spec_params$n <- n
DataFakeR::unique_sample(
do.call(books, spec_params),
spec_params = spec_params, unique = unique
)
}
set_faker_opts(
opt_simul_spec_character = opt_simul_spec_character(book = simul_spec_character_book)
)Source schema (and check table and column dependencies)
options("dfkr_verbose" = TRUE) # set `dfkr_verbose` option to see the workflow progress
sch <- schema_source("schema_books.yml")
schema_plot_deps(sch)
schema_plot_deps(sch, "books")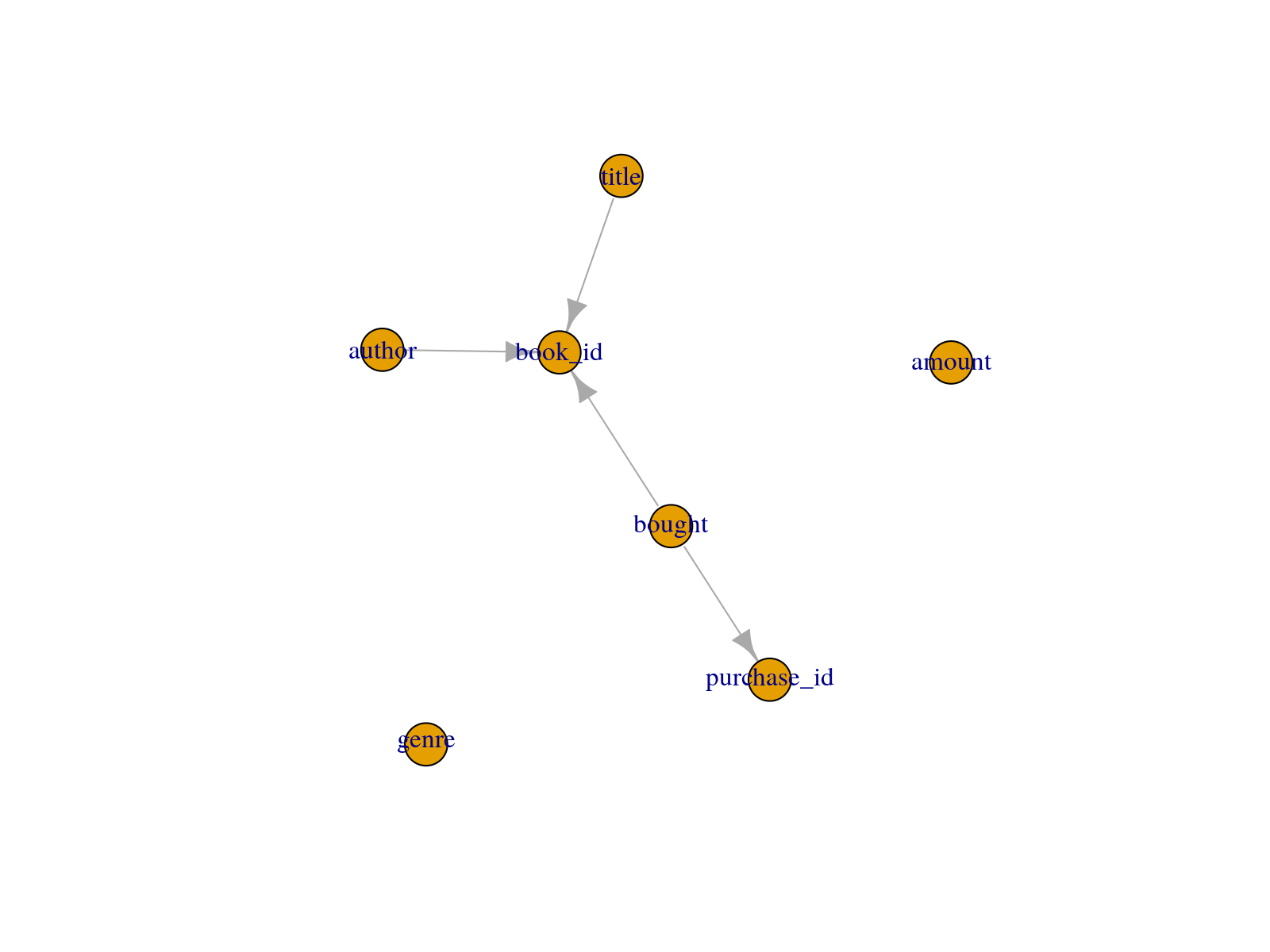
Run data simulation
sch <- schema_simulate(sch)
#> =====> Simulating table 'books' started..
#> ===> Simulating column 'author' started..
#> ===> Simulating column 'title' started..
#> ===> Simulating column 'genre' started..
#> ===> Simulating column 'bought' started..
#> ===> Simulating column 'amount' started..
#> ===> Simulating column 'book_id' started..
#> ===> Simulating column 'purchase_id' started..
#> =====> Simulating table 'borrowed' started..
#> ===> Simulating column 'book_id' started..
#> ===> Simulating column 'user_id' started..Check the results
schema_get_table(sch, "books")
#> # A tibble: 10 × 7
#> book_id author title
#> <chr> <chr> <chr>
#> 1 DormAmus2021 Dorman Abshire Amusing In Common Forest
#> 2 Dr. Symb2020 Dr. Montie Kihn Symbols In My Future
#> 3 SharAmus2021 Sharde Howell MD Amusing With Your Forest
#> 4 Dr. Lear2020 Dr. Maggie Lind Learning From A Storm
#> 5 NathSmil2020 Nathanael Upton-Prosacco Smile Of Common Future
#> 6 AnasSmil2021 Anastacia Dickens Smile In Common Forest
#> 7 RyleSymb2020 Ryleigh Brekke Symbols From Mysterious Storm
#> 8 HortAmus2020 Hortense Rosenbaum Amusing Before Common Technology
#> 9 MariHidi2021 Mariana Auer-Sauer Hiding On The Forest
#> 10 TrisSmil2021 Tristen Larkin Smile With The South
#> genre bought amount purchase_id
#> <chr> <date> <int> <chr>
#> 1 Adventure 2021-04-13 17 purchase_2021-04-13
#> 2 Horror 2020-03-16 81 purchase_2020-03-16
#> 3 Adventure 2021-01-06 55 purchase_2021-01-06
#> 4 Adventure 2020-02-02 NA purchase_2020-02-02
#> 5 Adventure 2020-04-13 93 purchase_2020-04-13
#> 6 Romance 2021-03-02 2 purchase_2021-03-02
#> 7 Horror 2020-08-09 42 purchase_2020-08-09
#> 8 Adventure 2020-10-12 NA purchase_2020-10-12
#> 9 Horror 2021-05-27 47 purchase_2021-05-27
#> 10 Horror 2021-05-30 72 purchase_2021-05-30
schema_get_table(sch, "borrowed")
#> # A tibble: 30 × 2
#> book_id user_id
#> <chr> <chr>
#> 1 DormAmus2021 PKPFJGYlKQ
#> 2 SharAmus2021 YiitBNRqgN
#> 3 RyleSymb2020 ZmFaiKZrsn
#> 4 RyleSymb2020 hKKanzSLlW
#> 5 AnasSmil2021 vvTGnzCNAP
#> 6 DormAmus2021 BZcsAzAjzm
#> 7 RyleSymb2020 gEfcYAuUVw
#> 8 SharAmus2021 oVcYOaJXBc
#> 9 HortAmus2020 YDCQQTGlce
#> 10 AnasSmil2021 uLrpKuAFVd
#> # … with 20 more rowsAcknowledgment
The package was created thanks to Roche support and contributions from RWD Insights Engineering Team.
Special thanks to:
- Adam Foryś for technical support, numerous suggestions for the current and future implementation of the package.
- Adam Leśniewski for challenging limitations of the package by providing multiple real-world test scenarios (and wonderful hex sticker!).
- Paweł Kawski for indication of initial assumptions about the package based on real-world medical data.
- Kamil Wais for highlighting the need for the package and its relevance to real-world applications.
Lifecycle
DataFakeR 0.1.3 is at experimental stage. If you find bugs or post an issue on GitHub page at https://github.com/openpharma/DataFakeR/issues
Getting help
There are two main ways to get help with DataFakeR
- Reach the package author via email: krystian8207@gmail.com.
- Post an issue on our GitHub page at https://github.com/openpharma/DataFakeR/issues.